



Содержание
Перейти к:
https://doi.org/10.35266/1999-7604-2024-3-7
Перейти к:
На основе анализа методов мягкой кластеризации документов и вероятностных распределений терминов и тем рассмотрены вычислительные методы и инструменты моделирования динамики политематических потоков в многомерном информационном пространстве. Предложена оптимизированная стохастическая модель динамики мягкой кластеризации сетей знаний в информационном пространстве, структурированном на основе семантических связей в текстах определенной предметной области, извлеченных из наукометрических и библиографических баз данных. На основе теоретической модели разработан алгоритм и методика его применения, с помощью которой возможно применение расширенной текстовой аналитики, включая выявление скрытых тем и прогнозирование трендов. Разработанная методика позволяет c определенным уровнем научной объективности осуществлять прогнозирование новых технологий и актуальных научных направлений в заданной определенной предметной исследовательской области, в том числе для решения теоретических, прикладных и управленческих задач. На основании практических результатов, полученных в работе, разработан глоссарий прогностических терминов «Информационные технологии и коммуникации», который рекомендован к применению в учебном процессе системы общего и профессионального образования.
Попов О.Р., Крамаров С.О. Оптимизация при вероятностном тематическом моделировании технологической прогностической информации. Вестник кибернетики. 2024;23(3):56-69. https://doi.org/10.35266/1999-7604-2024-3-7
Popov O.R., Kramarov S.O. Optimization in probabilistic topic modeling of technological predictive information. Proceedings in Cybernetics. 2024;23(3):56-69. (In Russ.) https://doi.org/10.35266/1999-7604-2024-3-7
Развитие стохастического анализа доказало важность подхода, основанного на стохастическом описании природы многих сложных физических и технологических систем. Наблюдается расширение использования вероятностных методов и для прогнозирования развития научных областей. В настоящее время сформировался целый блок научно-технических дисциплин, имеющих общую системную ориентацию, задающую относительно них особую плоскость существования искусственно создаваемых сложных систем. Особый интерес представляют междисциплинарные области взаимных пересечений наук и технологий. На этих стыках используются инструменты одной области для продвижения другой.
Наиболее развитыми в динамике процесса представляются информационно-коммуникационные технологии (ИКТ). Чаще всего именно эти технологии поставляют инструменты для развития других технологий через возможности имитационного компьютерного моделирования различных процессов.
Для описания процессов, учитывающих сложные нелинейные механизмы, необходимо использование специального подхода, связанного с вероятностным тематическим моделированием. Вероятностные тематические модели осуществляют «мягкую кластеризацию» (soft clustering), относя документ к нескольким кластерам-темам с некоторыми вероятностями.
Проблема вероятностного моделирования динамики мягкой кластеризации тематических информационных потоков, особенно с учетом внутри- и межструктурных взаимодействий, а также многих метаданных (модальностей), признаются открытыми научными проблемами [1–3].
Актуальной практической задачей является проблема моделирования стохастических процессов взаимодействия политематических информационных потоков, структурированных на основе семантических связей определенной предметной области, для прогнозирования новых технологий и научных направлений. В качестве предметной области выбраны прогнозируемые ИКТ, которые находятся в кластерах пересечения научных инноваций и дают рекомендации для исследований по другим зрелым или появляющимся технологиям [4].
Основные вычислительные методы и инструменты, приводящие к автоматическому режиму обнаружения знаний и скрытых ассоциаций в публикациях, включая тематическое моделирование, подробно классифицируются в источнике [5]. Анализ на уровне темы распространения дополняет процесс поиска и фильтрации информации, помимо анализа на уровне термов.
Тематические модели используются в различных предметных областях и для различных задач, включая, например, менеджмент знаний [6], анализ кластеризации сообществ [7], автоматическое выявление новых новостных тем [8]. Достаточно редки публикации, отражающие использование данных методов для анализа научно-технологических инноваций.
Аналитический метод, позволяющий сгруппировать связанные термины и фразы, определить меняющиеся тематические акценты в сфере информатики и больших данных, составить технологическую дорожную карту (technology roadmap, TRM) предложен в источнике [9]. TRM прогнозирует будущие изменения в технологических темах и получает информацию для планирования научно-исследовательских и опытно-конструкторских работ, а также для стратегического управления. Однако данная работа представляет собой гибридный набор различных методик при отсутствии явной вычислительной модели. Для прогнозирования применяется сложный в реализации экспертный подход без автоматизации данных. Двумерное отображение семантической близости тем в виде «дорожной карты» является весьма упрощенным инструментом визуализации [10].
В источнике [11] на основе анализа обширной коллекция статей, опубликованных с 2000 по 2021 гг. на конференциях по машинному обучению и искусственному интеллекту (ИИ), реализуется задача ранней детекции трендовых научных тем. Обосновывается преимущество предлагаемого инкрементального метода вероятностного тематического моделирования, реализуемого на основе модели ARTM, в сравнении с популярными байесовскими и нейросетевыми подходами. В качестве примеров выявленных трендовых тем в машинном обучении приводятся «LSTM», «deep learning», «word2vec», «BERT», «fake news detection». Однако очевидные прикладные результаты работы модели не приводятся.
Потенциальной возможностью вероятностных подходов для решения актуальных прикладных научных задач в сфере технологий ИИ является информация о том, что в лаборатории машинного обучения и семантического анализа Института искусственного интеллекта МГУ обучили нейронную сеть для получения семантических векторных представлений (эмбеддингов) научных текстов на русском языке SciRus-tiny [12]. Это реализовано с помощью данных, предоставленных для обучения порталом eLIBRARY.RU, который содержит большое количество документов по множеству разнообразных научных тематик.
Полученные результаты показывают, что сжатое описание документа в виде вектора вероятностей тем содержит важнейшую информацию о семантике документа и может использоваться для решения многих нетривиальных задач текстовой аналитики, включая обнаружение латентной кластерной структуры в документах и выявление трендов в библиографических и патентных базах данных.
Вероятностная тематическая модель (probabilistic topic model) выявляет тематику коллекции документов, представляя каждую тему дискретным распределением вероятностей терминов, а каждый документ – дискретным распределением вероятностей тем.
Исходными данными для тематического моделирования является множество (коллекция) текстовых документов D и множество (словарь) терминов (термов) W. Под термами понимаются слова, нормальные формы слов, словосочетания или термины, в зависимости от того, какие виды предварительной обработки текстов были выполнены.
Каждый документ d ∈ D представляется последовательностью термов (w1, ..., wnd) из W, где nd – длина документа. Через ndw обозначается число вхождений терма w в документ d.
Существует конечное множество тем T и коллекция порождается дискретным распределением p(d,w,t) на D × W × T. Документы d и термы w являются наблюдаемыми переменными, тема t – латентной переменной, т. е. каждое вхождение терма w в документ d связано с некоторой неизвестной темой t из заданного конечного множества T.
Для каждой темы t и документа d зададим вероятность темы в документе p(t|d). То же самое сделаем для слов и тем: p(w|t) – вероятность встретить слово w в теме t. Распределение вероятностей термов p(w|d,t) зависит только от темы t, но не от документа d (гипотеза условной независимости):
p(w|d,t) = p(w|t).(1)
Распределение терминов в документе p(w|d) описывается вероятностной смесью распределений терминов в темах φωt = p(w|t) с весами θtd = p(t|d):
p(w|d) = p(w|d,t)p(t|d) = p(w|t)p(t|d) = φωt θtd.(2)
Вероятностная порождающая или генеративная модель (2) описывает процесс порождения коллекции по известным распределениям p(w|t) и p(t|d).
Построить тематическую модель коллекции является обратной задачей [13], что означает найти по заданной коллекции D множество тем T, условные распределения термов φωt = p(w|t) для каждой темы t ∈ T с весами θtd = p(t|d) для каждого документа d ∈ D.
Равенство (2) можно представить в виде матрицы P = (pdw)W×D частот слов документа (как часто каждое слово встречается в каждом документе), которая затем записывается как произведение двух матриц меньших размеров Φ = (φωt)W×T – матрицы термов тем и Θ = (θtd)T×D – матрицы тем документов. Матрица P известна, так как это исходные данные, и имеет в общем случае полный ранг, поэтому не может быть в точности равна ΦΘ. Правая часть равенства представляет собой произведение двух неизвестных матриц. Построение вероятностной тематической модели является решением задачи поиска приближенного низкорангового стохастического матричного разложения P ≈ ΦΘ (рис. 1).
Столбцы этих матриц в целом можно рассматривать как нормализованные, то есть задача декомпозиции матрицы может быть приведена к максимизации логарифма правдоподобия [14]:
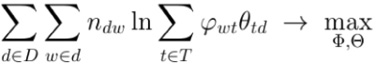 (3)
(3)
при ограничениях неотрицательности и нормировки всех столбцов φt, θd:
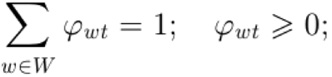
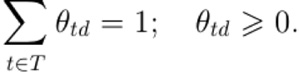 (4)
(4)
Решение задачи матричного разложения будет неуникальным. Согласно теории регуляризации А. Н. Тихонова [15], решение некорректно поставленной операторной задачи возможно доопределить и сделать устойчивым. Для этого следует наложить некоторые дополнительные ограничения на R(Φ, Θ), называемые регуляризаторами. Функция регуляризатора должна быть непрерывно дифференцируемой. К задаче максимизации логарифмического правдоподобия будет добавлен новый компонент, и задача оптимизации примет вид:
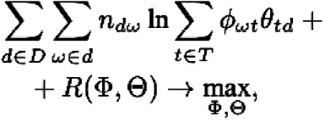 (5)
(5)
Первая модель, называемая pLSA (вероятностный латентный семантический анализ), предложенная в источнике [16], предполагала, что R(Φ, Θ) = 0.
В дальнейшем широкое применение получили два подхода к регуляризации вероятностных генеративных моделей: скрытое распределение Дирихле (latent Dirichlet allocation, LDA) [17], основанный на байесовском выводе, и, более классическая, аддитивная регуляризация тематических моделей, которая, как следует из названия, лежит в основе ARTM.
Модель LDA предполагает байесовскую регуляризацию таким образом, что:
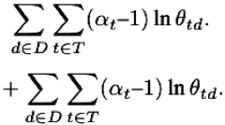 (6)
(6)
Здесь βω и αt являются гиперпараметрами с положительной настройкой. Модель LDA предполагает, что векторы документа θtd генерируются одним и тем же распределением вероятностей на нормализованных векторах, а распределение берется из семейства распределений Дирихле с параметром α [7]. Аналогично, векторы темы φωt генерируются распределением Дирихле с параметром β.
Распределение Дирихле существенно упрощает байесовский вывод, и большинство моделей строятся с его использованием.
Однако следует обратить внимание на ряд проблем, связанных с байесовской регуляризацией: необходимо оптимизировать гиперпараметры, инициализировать параметр βω для новых терминов и обеспечивать разреженность, при том, что обнулять параметры φωt и θtd невозможно.
Введение других инструментов приближенного байесовского вывода (вариационный вывод, семплирование Гиббса, распространение ожидания) не позволяет легко комбинировать модели и снимать ограничения, связанные с выбором распределений Дирихле. Для каждой новой модели приходится заново выполнять математические выкладки и программную реализацию [13].
Альтернативой байесовскому подходу является метод аддитивной регуляризации тематических моделей (ARTM) [18]. Это приложение классической теории регуляризации некорректно поставленных задач [15] к тематическому моделированию.
Аддитивная регуляризация тематических моделей (ARTM) основана на максимизации линейной комбинации логарифма правдоподобия и нескольких регуляризаторов Ri(Φ, Θ), i = 1, …, k:
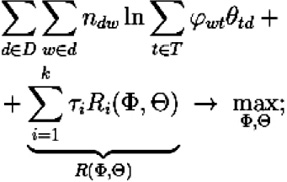 (7)
(7)
при прежних ограничениях (4), где τi – неотрицательные коэффициенты регуляризации.
Построение многофункциональных тематических моделей существенно упрощается благодаря аддитивности регуляризаторов [18]. Функционал максимизации правдоподобия (3) позволяет добавить не один метод регуляризации, а несколько, придавая вес каждому. Этот подход выражает суть аддитивности регуляризации и, как следует из названия, лежит в основе ARTM.
Таким образом, ARTM это не инкрементное улучшение одной тематической модели, а общий подход к тематическому моделированию как к задаче многокритериальной оптимизации.
В подходе АРТМ распределение Дирихле является не универсальным, а одним из возможных регуляризаторов. В качестве базовой модели логичнее брать pLSA, не имеющую собственных регуляризаторов, которые можно добавлять из модульной расширяемой библиотеки в зависимости от поставленной проблемы.
С точки зрения поставленных в работе прикладных исследовательских задач, такой подход дает преимущества. В первую очередь это касается оптимизации стратегий построения иерархических тематических моделей, включая динамические модели, которые выявляют закономерности развития кластеров не только внутри мультидисциплинарных корпусов, но и с течением времени.
При формировании базовых принципов построения многофункциональной тематической модели (далее «Модель») необходимо учитывать максимум дополнительной информации, особенности семантики и предмета текстовой коллекции. С точки зрения стратегий оптимизации при вероятностном тематическом моделировании выделяются следующие факторы:
Общая схема многофункциональной модели обработки информационных процессов, рассматриваемой как большой научный проект science data, представлена на рис. 2. В Модели выделяются три блока, характерные также для разработки и проектирования проекта big data с использованием технологий глубинного анализа текстов (Text Mining) и нахождения при этом закономерностей и трендов:
В рамках данных блоков сформированы пять взаимосвязанных этапов алгоритма Модели:
Заданный алгоритмический подход преследует цель обеспечить максимальную объективность поиска и скорость, с которой он позволяет углубиться в выбранную предметную область исследований.
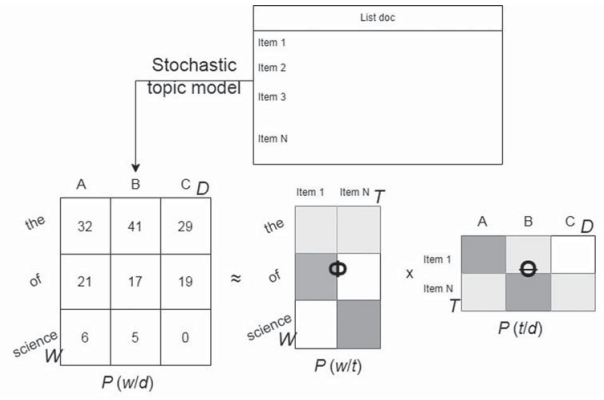
Рис. 1. Построение тематической модели: решение задачи приближенного стохастического матричного разложения P ≈ ΦΘ
Примечание: составлено авторами на основании данных, полученных в исследовании.
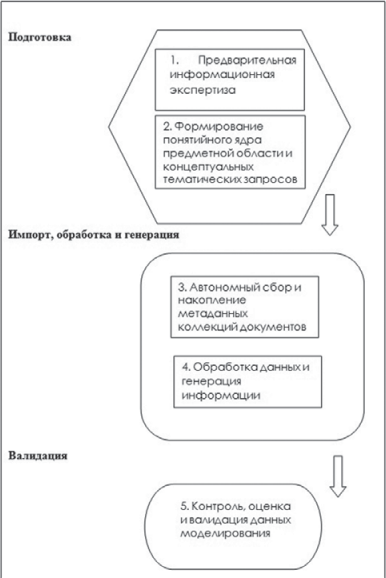
Рис. 2. Общая схема моделирования обработки информационных процессов как научного проекта science data
Примечание: составлено авторами на основании данных, полученных в исследовании.
На первом подготовительном этапе практической реализации Модели используется авторская методика расчета показателя уровня зрелости самоорганизующихся интеллектуальных систем «SML», интегрирующего в себе показатели «технологические уровни готовности» (TPL) и «уровни социоэкономической адаптированности» (SPL) прогнозируемых технологий, входящих в исследуемую социотехническую систему [19].
В целях определения базовых структур предметной области экспертным методом выделены категории перспективных направлений развития ИКТ, соответствующих определенному уровню SML-матрицы. Например, в таблице приведены выделенные в рамках 4 категорий 22 перспективных направления развития информационно-коммуникационных технологий, соответствующих четвертому уровню:
Далее, исходя из предложенного подхода к формированию понятийного ядра предметной области, разработан алгоритм, применимый к задаче формирования «словаря прогностических терминов» [21].
Данный алгоритм позволяет на базе внешних сервисов (например, «Википедии») формировать словарь контекстно-близких терминов по отношению к изначально заданному термину. При этом задается набор изначальных терминов, и по результатам их обработки формируется полноценный словарь. Алгоритм оценивает «вес» близости терминов по отношению к изначальному термину. Ранжирование терминов выполняется по средней арифметической сумме оценок алгоритмов PageRank и HITS.
В процессе работы алгоритма набор собранных терминов группируется по категориям технологий, заданных программой исследования.
На рис. 3 представлена демонстрация работы алгоритма на примере графа, созданного по отношению к первичному термину «quantum computing» (квантовые вычисления).
По результатам работы алгоритма могут быть выведены различные варианты сводных списков терминов, как общих, так и структурированных по категориям технологий.
На основе глоссария прогностических терминов сформирована база концептуальных тематических запросов в сети знаний, представляющих актуальные общедоступные наукометрические и библиографические базы данных (ББД), научные и новостные научно-технические порталы, тематические сетевые ресурсы, тезаурусы.
Уровень достоверности получаемой информации может быть повышен за счет формирования комбинированного алгоритма сбора коллекции текстовых данных из высокоавторитетных качественных исследовательских баз данных (БД), таких как Google Scholar, arXiv, Springer Link, eLIBRARY.Ru, CyberLeninka, за определенный период времени.
Наукометрические индикаторы, обработанные в выбранной библиографической БД по специальной формуле, представляют собой информационную основу для автономного сбора и накопления метаданных коллекции.
Для извлеченных публикаций автоматически выгружаются их полные библиографические описания в форматах .csv и .xlsx для дальнейшей обработки и интеллектуального текстового анализа. По каждой записи может быть выдана информация, включающая полные «выходные данные», количество цитируемых в публикации источников, различные вторичные поля, несущие справочную информацию. Фрагмент основных информационных полей (Global Number, Time, Title, Authors, Abstract) библиографических данных по запросу «quantum computing» в ББД Google Scholar показан на рис. 4.
Сбор документов осуществляется в автоматическом режиме, с обработкой полученных исходных данных в соответствии с определенными правилами и сохранением метаданных. Выходные данные препроцессора документа представляют собой набор «чистого» текстового контента со связанными метаданными.
Обработанные текстовые документы передаются на вход многофункциональной системы обработки данных, генерации и визуализации информации.
Модуль тематического моделирования (BigARTM, Gensim-LDA) автоматически выводит набор скрытых тем. Результаты анализа темы, включая ключевое слово темы, дистрибутивы и распределения по темам документов, также сохраняются и индексируются во время индексации тем.
В результате работы алгоритма на данном этапе темпоральная (датированная) коллекция текстовых документов систематизируется по двум уровням:
- в соответствии с базовыми концепциями тематического запроса;
- в соответствии с проведенным тематическим анализом документов, сформированных внешней ББД в ответ на запрос.
Автономный и сетевой режимы ориентированы на решение как фундаментальных исследовательских задач, так и прикладных интересов пользователей информационного ресурса в процессе активного взаимодействия с системой. В данном основном блоке реализованы базовые процессы обработки big data, генерации новой информации и ее визуального представления с целью нахождения при этом закономерностей и прогностических трендов.
Чтобы отслеживать появление новых тем, для каждого временного шага в ББД обновляются данные. При поступлении новой порции документов D’ словарь пополняется новыми терминами W’ и могут образоваться новые темы T’. Основной принцип выявления научных трендов заключается в том, что новая лексика, появившаяся в новых документах, относится преимущественно к новым темам [11].
Темпоральное исследование кластерообразования, связанного с научной областью квантовых вычислений (quantum computing) в период 1980–2023 гг., приведено на рис. 5.
Анализ динамики тематических данных, интегрированных суммарно в 10 кластеров, показывает активное кластерообразование в новейший период (2020–2023 гг.) в области кластеров C6 («новые технологии»), C7 («квантовая нейронная сеть») и С10 («квантовое шифрование изображения») (рис. 3). Так, область кластера С7 пополняется такими терминами, как «квантовая информация», «квантовые данные», «классификация изображений», «процессор», «глубокая нейронная сеть», «сверточная нейронная сеть». В области кластера С10 можно обнаружить «шифрование цветного изображения», «логистическая карта», «схема квантового шифрования изображения», «квантовая репрезентативная модель». Использование новой, специфичной для данной научной области, лексики релевантно отражает постепенное вхождение новых квантовых информационных технологий, новых архитектур квантовых процессоров и симуляторов, устройств передачи квантовой информации, отражающих сложную динамику новейших квантовых систем и коммуникаций.
Особенностью выбранной методики валидации данных является рассмотрение, помимо классических мер оценки тематического моделирования (перплексии, когерентности, разреженности), критериев, одновременно выступающих индикаторами развития исследовательской модели.
Исходя из выбранного подхода к построению Модели, предложена модифицированная методика количественной оценки релевантности динамически выявленных скрытых тем начальному запросу (ключевому слову или концепту) [22].
Критерием релевантности темы понятию является существование между ними взаимно однозначного соответствия. Для выявления степени смещения выявляются 4 типа смещения:
- модель не выявляет темы;
- модель производит смешанные темы;
- ключевые слова в теме отсутствуют;
- повторяются среди скрытых тем.
На первом этапе автоматизированная оценка сходства между темами и концепциями рассчитывается с использованием трех распространенных мер сходства: косинусной, ранговой корреляции Спирмена и KL-дивергенции.
Далее проводится этап сравнительной экспертной оценки совпадений тем и концепций и преобразования оценок сходства в вероятности совпадения.
Составляется матрица размера n × m всех возможных пар между n ключевыми словами и m выявленными темами. Каждая запись p(s,t) рассматривается как независимая случайная величина Бернулли, представляющая вероятность совпадения того, что эксперт, изучающий распределения соответствия понятия s с темой t, ответит, что они релевантны. Каждой паре n × m присваивается рейтинг {1, 0,5, 0} для каждого ответа {совпадение, частичное совпадение, отсутствие совпадения}. Пара считается совпадающей, если ее средний рейтинг превышает 0,5.
В результате применения данной методики количественно оценивается и анализируется вероятность соответствия концепта прогнозируемой технологии латентным политематическим потокам, извлеченным и структурированным из научно-технического информационного пространства.
Для дальнейшего анализа качества стохастического моделирования при кластеризации данных и максимизации выявления трендов новых технологий проводится серия экспериментов, где сравнительно рассматриваются вероятностные тематические модели, такие как PLSA, LDA, ARTM [18] с базовыми регуляризаторами матрицы Φ, и глубокие нейронные сети, в частности BERTopic [11][12].
В рамках заданной предметной области будут исследованы возможности интеграции тематического моделирования с глубокими нейросетевыми моделями языка, моделями внимания и архитектуры трансформеров.
Таблица
Категории перспективных направлений развития ИКТ, соответствующих четвертому уровню SML-матрицы
|
I |
Human – computer interfaces |
|
|
1 |
ambient intelligence |
интеллектуальная среда |
|
2 |
brain – computer interface |
интерфейс «мозг– компьютер» |
|
3 |
city brain |
городской мозг |
|
4 |
semantic web |
семантический веб |
|
5 |
smart city |
умный город |
|
II |
Computing engineering |
|
|
1 |
exascale computing |
масштабные вычисления |
|
2 |
neuromorphic engineering |
нейроморфная инженерия |
|
3 |
optical computing |
оптические (фотонные) вычисления |
|
4 |
quantum computing |
квантовые вычисления |
|
III |
Memory and data storage technologies |
|
|
1 |
3D optical data storage |
3D оптическое хранение данных |
|
2 |
DNA digital data storage |
цифровое хранилище данных ДНК |
|
3 |
holographic data storage |
голографическое хранилище данных |
|
4 |
patterned media |
узорчатые носители |
|
5 |
phase-change memory |
память с фазовым переходом |
|
6 |
quantum memory |
квантовая память |
|
IV |
Electronics and communications |
|
|
1 |
atomtronics |
атомтроника |
|
2 |
carbon nanotube field-effect transistor |
полевой транзистор из углеродных нанотрубок |
|
3 |
Li-Fi (Light Fidelity) |
Li-Fi |
|
4 |
memristor |
мемристор, мемтранзистор, мемистор, транситор |
|
6 |
software-defined radio |
программно-определяемое радио |
|
7 |
spintronics |
спинтроника, твистроника, валлейтроника |
Примечание: составлено по источнику [21].
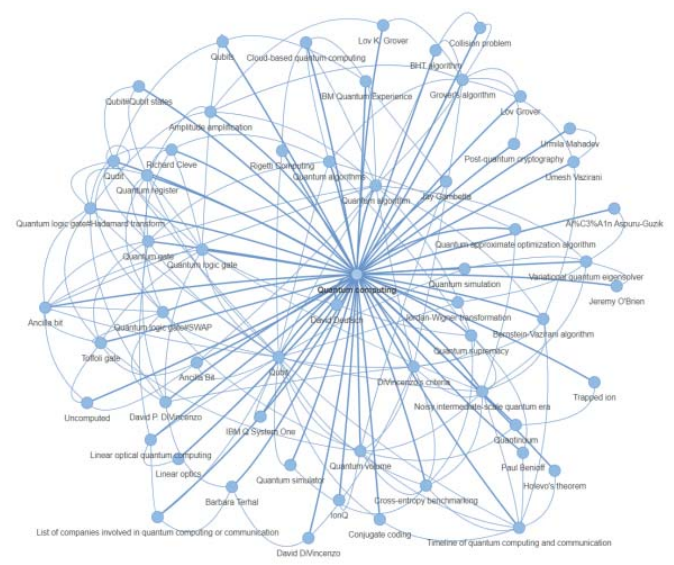
Рис. 3. Визуализация графа терминов/словосочетаний, полученных на основе входного термина «quantum computing»
Примечание: составлено по источнику [21].
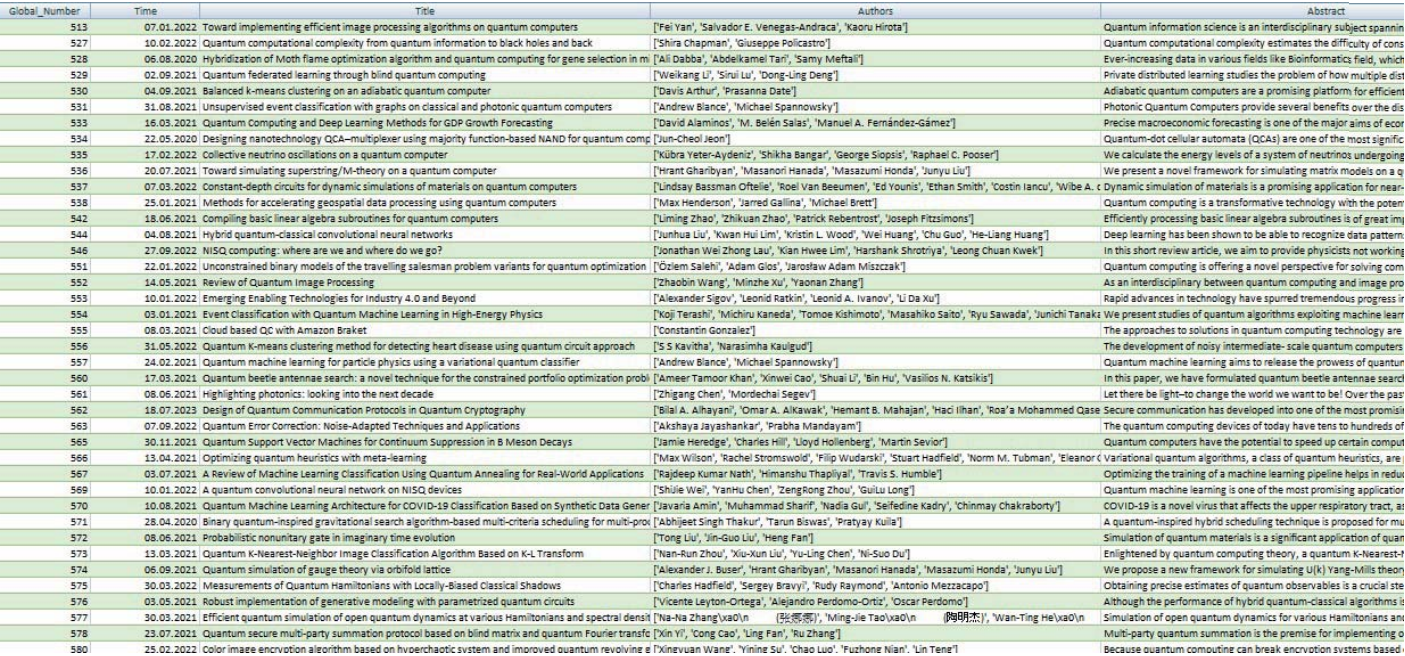
Рис. 4. Фрагмент вывода библиографического описания по запросу «quantum computing»
Примечание: составлено авторами на основании данных, полученных в исследовании.
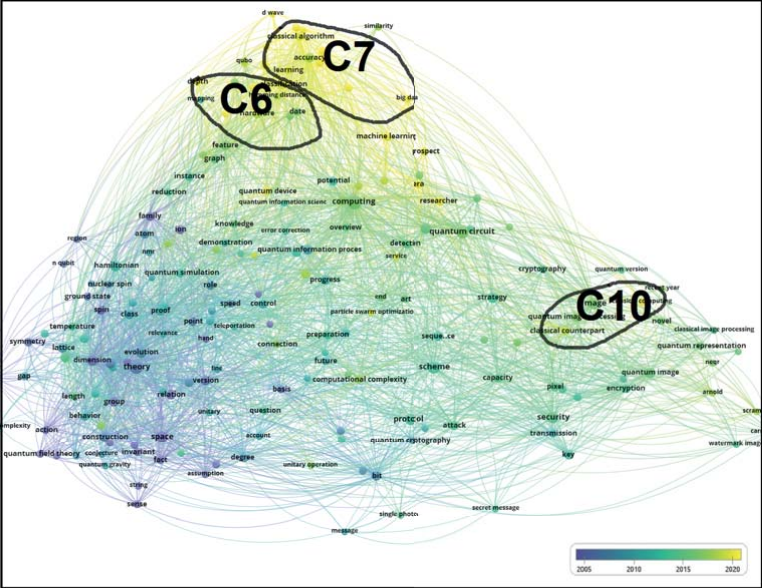
Рис. 5. Карта визуализации VOSviewer, показывающая динамику кластеризации тематических данных в период 1980–2023 гг. в области термина «quantum computing» (квантовые вычисления): цветовая шкала в правом нижнем углу визуализации, отображающая временную оценку данных, варьируется фиолетовым (до 2005 г.), зеленым (период 2010–2015 гг.), желтым (после 2020 г.)
Примечание: составлено авторами на основании данных, полученных в исследовании.
1. Shadrova A. Topic models do not model topics: epistemological remarks and steps towards best practices // Journal of Data Mining & Digital Humanities. 2021. https://doi.org/10.46298/jdmdh.7595.
2. Churchill R., Singh L. The evolution of topic modeling // ACM Computing Surveys. 2022. Vol. 54, no. 10s. P. 1–35. https://doi.org/10.1145/3507900.
3. Zhao H., Phung D., Huynh V. et al. Topic modelling meets deep neural networks: A survey // Proceedings of the Thirtieth International Joint Conference on Artifi cial Intelligence, IJCAI-21. 2021. P. 4713–4720. https://doi.org/10.48550/arXiv.2103.00498.
4. Бодрунов С. Д. Ноономика : моногр. М. : Культурная революция, 2018. 432 с.
5. Thilakaratne M., Falkner K., Atapattu T. A systematic review on literature-based discovery: general overview, methodology, & statistical analysis // ACM Computing Surveys. 2019. Vol. 52, no. 6. P. 1–34. https://doi.org/10.1145/3365756.
6. Zelenkov Yu. The topic dynamics in knowledge mana gement research // Knowledge Management in Orga nizations (KMO 2019): Proceedings of the 14th International Conference. 2019. P. 324–335. https:// doi.org/10.1007/978-3-030-21451-7_28.
7. Gorshkov S., Ilyushin E., Chernysheva A. et al. Using topic modeling for communities clusterization in the VKontakte social network // International Journal of Open Information Technologies. 2021. Vol. 9, no. 5. P. 12–17.
8. Zhang J., Ghahramani Z., Yang Y. A probabilistic model for online document clustering with application to novelty detection // Advances in neural information processing systems. 2004. Vol. 17.
9. Zhang Y., Zhang G., Chen H. et al. Topic analysis and forecasting for science, technology and innovation: Methodology with a case study focusing on big data research // Technological forecasting and social change. 2016. Vol. 105. P. 179–191.
10. Айсина Р. М. Обзор средств визуализации тематических моделей коллекций текстовых документов // Машинное обучение анализ данных. 2015. Т. 1, № 11. С. 1584–1618.
11. Герасименко Н. А., Чернявский А. С., Никифорова М. А. и др. Инкрементальное обучение тематических моделей для поиска трендовых тем в научных публикациях // Доклады Российской академии наук. Математика, информатика, процессы управления. 2022. Т. 508, № 1. С. 106–108.
12. Герасименко Н. ruSciBench – бенчмарк для оценки эмбеддингов научных текстов. URL: https://habr.com/ru/articles/781032/ (дата обращения: 25.03.2024).
13. Большакова Е. И., Воронцов К. В., Ефремова Н. Э. и др. Автоматическая обработка текстов на естественном языке и анализ данных. М. : НИУ ВШЭ, 2017. 268 с.
14. Воронцов К. В., Потапенко А. А. Регуляризация, робастность и разреженность вероятностных тематических моделей // Компьютерные исследования и моделирование. 2012. Т. 4, № 4. С. 693–706.
15. Тихонов А. Н., Арсенин В. Я. Методы решения некорректных задач. 3-е изд., испр. М. : Наука, 1986. 286 с.
16. Hofmann T. Probabilistic latent semantic indexing // Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval. 1999. P. 50–57.
17. Blei D. M., Ng A. Y., Jordan M. I. Latent dirichlet allocation // Journal of Machine Learning Research. 2003. Vol. 3. P. 993–1022.
18. Воронцов К. В., Потапенко А. А. Аддитивная регуляризация тематических моделей // Доклады Академии наук. 2014. Т. 456, № 3. С. 268–271.
19. Попов О. Р. Адаптация мировых практик к проблеме долгосрочного технологического прогнозирования состояния самоорганизующихся интеллектуальных систем // Интеллектуальные ресурсы – региональному развитию. 2021. № 2. С. 91–98.
20. Крамаров С. О., Попов О. Р., Джариев И. Э. и др. Динамика формирования связей в сетях, структурированных на основе прогностических терминов // Russian Technological Journal. 2023. Т. 11, № 3. С. 17–29.https://doi.org/10.32362/2500-316X-2023-11-3-17-29.
21. Попов О. Р., Гросу А., Крамаров С. О. Комплексный сетевой алгоритм формирования глоссария контекстно-близких прогностических терминов // Современные информационные технологии и ИТ-образование. 2023. Т. 19, № 3. URL: http://sitito.cs.msu.ru/index.php/SITITO/article/view/999 (дата обращения: 25.03.2024).
22. Chuang J., Gupta S., Manning C. et al. Topic model diagnostics: Assessing domain relevance via topical alignment // International conference on machine learning. 2013. P. 612–620.
кандидат технических наук, доцент
доктор физико-математических наук, профессор
Попов О.Р., Крамаров С.О. Оптимизация при вероятностном тематическом моделировании технологической прогностической информации. Вестник кибернетики. 2024;23(3):56-69. https://doi.org/10.35266/1999-7604-2024-3-7
Popov O.R., Kramarov S.O. Optimization in probabilistic topic modeling of technological predictive information. Proceedings in Cybernetics. 2024;23(3):56-69. (In Russ.) https://doi.org/10.35266/1999-7604-2024-3-7
628412, Ханты-Мансийский автономный округ – Югра,
г. Сургут, пр. Ленина, 1.
БУ ВО ХМАО-Югры «Сургутский государственный университет»
Email: science.jоurnals@surgu.ru











