


Содержание
Перейти к:
 Валентин Валерьевич Брыкин,
Михаил Яковлевич Брагинский,
Дмитрий Викторович Тараканов,
Инесса Леонидовна Назарова
Валентин Валерьевич Брыкин,
Михаил Яковлевич Брагинский,
Дмитрий Викторович Тараканов,
Инесса Леонидовна Назарова https://doi.org/10.35266/1999-7604-2024-2-3
Перейти к:
В данной работе используется адаптивная нейро-нечеткая система ANFIS для классификации восьми болезней растений. В качестве входных данных системы применяются текстурные признаки Харалика, извлеченные из изображений растений. Обучение ANFIS проводилось с использованием гибридного алгоритма, сочетающего обратное распространение ошибки и градиентный спуск. Эффективность ANFIS оценивалась на тестовом наборе посредством вычисления точности, полноты и F1-меры. Полученные показатели подлежали сравнению с другими современными средствами классификации.
Брыкин В.В., Брагинский М.Я., Тараканов Д.В., Назарова И.Л. КЛАССИФИКАЦИЯ СОСТОЯНИЯ РАСТЕНИЙ С ИСПОЛЬЗОВАНИЕМ АДАПТИВНОЙ НЕЙРО-НЕЧЕТКОЙ ИНФЕРЕНЦИОННОЙ СИСТЕМЫ (ANFIS). Вестник кибернетики. 2024;23(2):23-30. https://doi.org/10.35266/1999-7604-2024-2-3
Brykin V.V., Braginsky M.Ya., Tarakanov D.V., Nazarova I.L. CLASSIFYING PLANTS’ HEALTH USING AN ADAPTIVE NEURO-FUZZY INFERENCE SYSTEM (ANFIS). Proceedings in Cybernetics. 2024;23(2):23-30. (In Russ.) https://doi.org/10.35266/1999-7604-2024-2-3
Сегодня цифровизация сельского хозяйства, где полевые условия контролируются с помощью автономных систем, набирает все большие обороты. При создании систем подобного рода необходимо решать задачи идентификации болезни растений, анализировать динамику их роста.
Задача выявления болезней растений, недостаток воды, микроэлементов на всех стадиях развития позволяет минимизировать экономические потери в агробизнесе. Таким образом, для решения вышеуказанной задачи необходимо использовать методы дистанционного мониторинга состояния растений, способных выявлять болезни растений с высокой точностью и скоростью.
Имеется большая потребность в новых технологиях, отслеживающих рост растений и прогнозирующих воздействие на него различных факторов. В большинстве случаев болезни можно проследить по состоянию побегов растения (стебля, листьев). Значит, идентификация растений, выявление болезней, анализ роста играют существенную роль в успешном выращивании агрономических культур.
Все операции, связанные с обработкой изображений, выполняются в цветовом пространстве RGB, являющемся одним из основных способов представления изображений.
Текстура наряду с цветом является самой важной особенностью, если необходимо обнаружить какой-либо объект. Это относится и к классификации состояния растений – любое заболевание отличается характерным распространением по организму и цветом. На основе расположения пикселей на изображении появляется возможность идентифицировать любой объект.
Существует множество способов текстурного анализа. Здесь используется метод текстурных признаков Харалика. Эти признаки рассчитываются на основе матрицы совпадения уровней серого (gray-level co-occurrence matrix, GLCM), являющейся оценкой плотности распределения вероятностей второго порядка p2 (P, Q, Z, Y), полученной по одному изображению в предположении, что плотность вероятности p2 зависит лишь от взаимного расположения P и Q. При этом Z является числом, обозначающим учет соседних пикселей, в том числе их расстояния от пикселя интереса. Y – значение ориентации пикселя интереса и соседних пикселей (в градусах) в интервале [0; 2π) с шагом π/4.
GLCM-матрица представляет собой текстурные свойства, но она неудобна при непосредственном анализе изображения [1–5]. Признаки Харалика, вычисляемые на ее основе, зарекомендовали себя куда лучше. В данной работе использовались 4 информативных признака, дающих наибольшую итоговую точность, из 14 возможных:
Контраст. Измеряет пространственную частоту изображения.
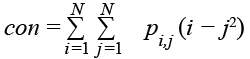 . (1)
. (1)
Несходство. Мера расстояния между парами пикселей в интересующей области.
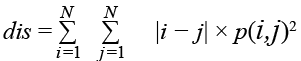 . (2)
. (2)
Энергия (второй угловой момент). Измеряет текстурную однородность изображения.
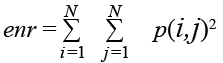 . (3)
. (3)
Однородность (обратный разностный момент). Измеряет однородность изображения, которая возрастает при уменьшении тона серого.
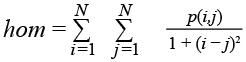 . (4)
. (4)
Адаптивная нейро-нечеткая инференционная система (ANFIS) – это гибридная интеллектуальная система, которая сочетает в себе принципы нечеткой логики и нейронных сетей. Она была разработана в 1993 г. Дж. С. Р. Янгом. ANFIS может быть использована для моделирования сложных нелинейных систем, классификации и прогнозирования [6–9].
Структура ANFIS обычно состоит из пяти слоев (рис. 1).
– Входной слой (Layer 1): получает входные данные и преобразует их в степени принадлежности к функциям принадлежности. В качестве такой функции используют, например, функцию Гаусса.
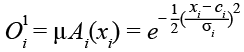 , (5)
, (5)
где с – центр функции принадлежности;
σ – ширина функции принадлежности.
– Слой нечеткого вывода (Layer 2): вычисляет веса правил на основе степеней принадлежности входных данных.
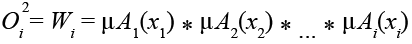 , (6)
, (6)
где Wi – вес i-го правила;
μAi (xi) – степень принадлежности входного значения xi функции принадлежности Ai.
– Нормализующий слой (Layer 3): нормализует веса правил.
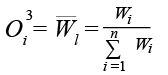 . (7)
. (7)
– Слой дефаззификации (Layer 4): вычисляет произведение нормализованного правила на выходную функцию.
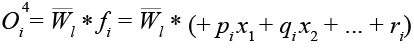 , (8)
, (8)
где 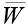 – результат уровня 3;
– результат уровня 3;
fi – выходное значение i-го правила;
(pi, qi, ri) – набор параметров следствия узла i.
– Слой вывода (Layer 5): вычисляет взвешенную сумму выходов всех правил.
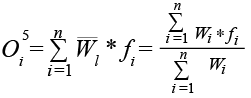 . (9)
. (9)
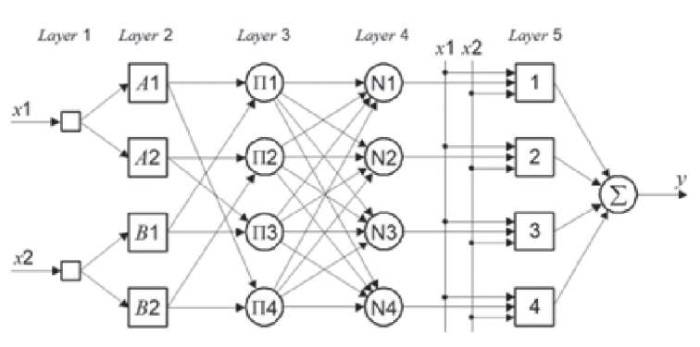
Рис. 1. Структура ANFIS
Примечание: составлено авторами.
Определения текущего состояния растения основано на решении задачи классификации цифровых изображений на основе анализа текстуры и цвета. Алгоритм классификации основан на совместном применении текстурных признаков Харалика и современных инструментов классификации.
Схема алгоритма представлена на рис. 2.
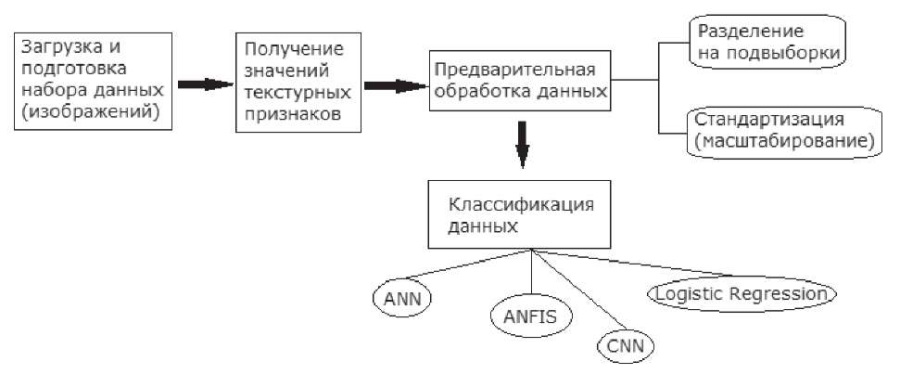
Рис. 2. Схема алгоритма классификации
Примечание: составлено авторами.
Как можно увидеть из рис. 2, после инициализации набора данных и его предварительной обработки из каждого изображения извлекаются текстурные признаки, которые передаются в качестве входных данных для классификационных методов.
Исходные данные приведены на рис. 3 и представляют собой набор цветных цифровых изображений, распределенных по директориям, имена которых соответствуют названиям классов. Изображения были предварительно подготовлены – приведены к единому размеру 256×256 пикселей и распределены поровну на каждый класс (сбалансированы по 2 200 единиц в каждом классе, суммарно 17 600 фотографий). Таким образом, количество директорий совпадает с числом классов, равным 8.
Датасет на рис. 3 был загружен с общедоступного ресурса по исследованию данных Kaggle.

Рис. 3. Классы исходных данных
Примечание: составлено авторами.
Так как исходное изображение представляет собой RGB-область размером 128×128 пикселей исходного изображения, для каждого из трех его каналов (красная, зеленая и синяя компоненты) строится симметричная нормированная GLCM-матрица в 256 оттенках серого. Значит, для целого изображения будет вычислено 3 GLCM-матрицы оттенков серого. В свою очередь, каждая такая матрица порождает 4 значения признаков Харалика, описанных ранее. Таким образом, одно цветное изображение будет описано вектором-строкой из 12 коэффициентов-признаков Харалика.
Для удобства восприятия и дальнейших расчетов все коэффициенты – а это массив размером m × k (где m = 17 600 – общее число изображений в наборе данных, k = 12 + 1 = 13 – итоговое количество признаков Харалика и метка класса, закодированная способом «label encoding») – были записаны в CSV-файл средствами библиотеки Pandas языка Python (рис. 4).
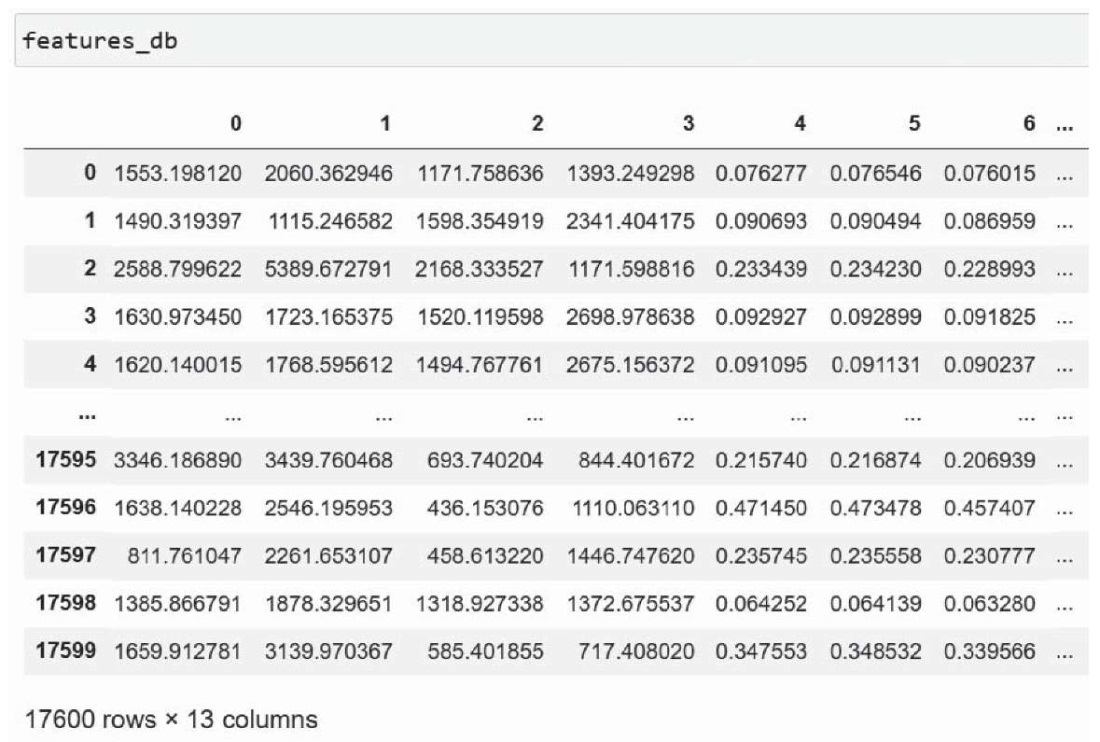
Рис. 4. Текстурные признаки Харалика для исходного датасета
Примечание: составлено авторами.
Стоит также упомянуть другие модули и библиотеки Python, задействованные в данной работе:
Os – для работы с операционной и файловой системами (загрузка и инициализация набора данных);
OpenCV – для анализа изображений;
NumPy – для работы с многомерными массивами;
Matplotlib – для визуализации данных и вычислений;
Anfis – для нечетких вычислений;
Scikit-Learn – для операций машинного обучения.
Фактически датафрейм из рис. 5 представляет собой готовую для дальнейших вычислений и решения основной задачи базу данных признаков изображений. Входными данными для обучения нейронной сети будут являться значения признаков Харалика (все столбцы датафрейма, кроме последнего), выходными – последний столбец датафрейма с закодированными метками классов.
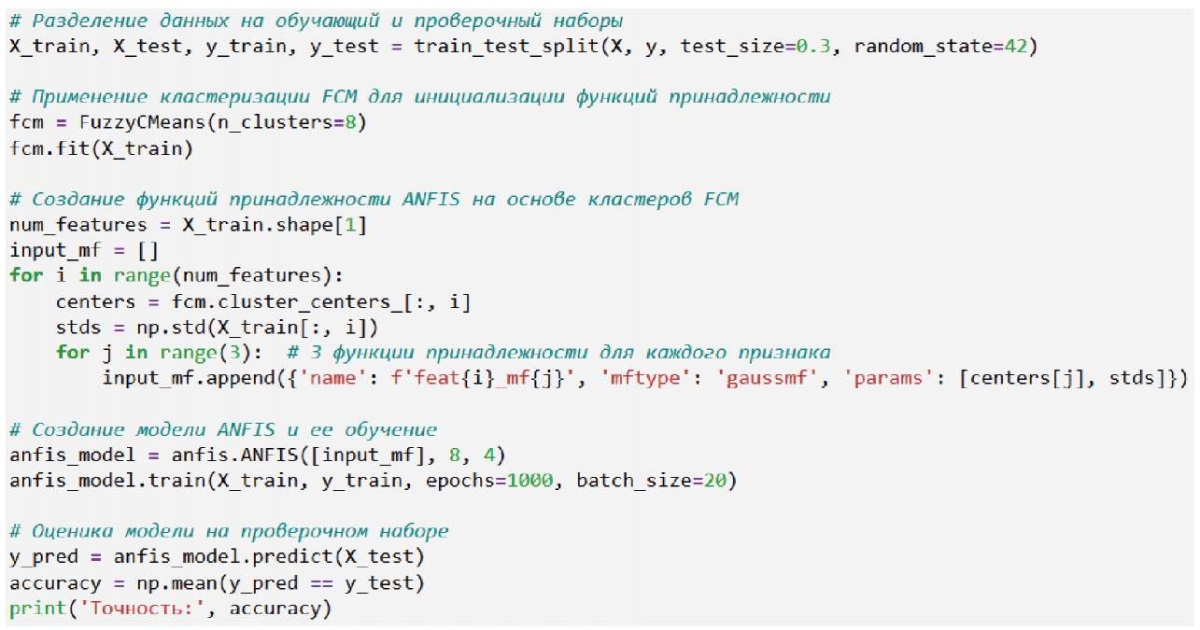
Рис. 5. Создание и обучение ANFIS
Примечание: составлено авторами.
Следующим шагом является предварительная обработка данных.
Во-первых, это разделение на обучающую и тестовую выборки в оптимальном соотношении 70:30.
Во-вторых, стандартизация: некоторые характеристики имеют широкий диапазон значений и в процессе классификации могут создать систематическую ошибку. Вспомогательный класс StandartScaler масштабирует данные так, чтобы они имели нулевое среднее значение и единичную дисперсию (μ = 0, σ = 1). Важно то, что здесь выполняется стандартизация лишь входных данных, поскольку выходные содержат только закодированные метки [5][6].
Создание модели ANFIS для восьмиклассовой классификации с 12 входными признаками Харалика состоит из следующих шагов.
Подготовка данных
– Собирается набор данных (изображений), помеченных 8 классами.
– Извлекается 12 признаков Харалика из каждого изображения (по 4 из каждой компоненты R, G, B).
– Набор данных разделяется на обучающий и проверочный наборы.
Создание функции принадлежности
– Выбирается тип функций принадлежности (в данном случае – гауссова).
– Определяется количество и местоположение функций принадлежности для каждого входного признака (далее для каждого признака используется 3 функции принадлежности).
Для инициализации начальных параметров функций принадлежности, таких как центры и стандартные отклонения, в данной работе используется метод нечеткой кластеризации C-средних. Это помогает избежать ручной настройки параметров и обеспечивает более точную и эффективную классификацию.
Расчет степеней принадлежности
– Для каждого обучающего и тестового изображения вычисляется степень принадлежности каждого признака каждой функции принадлежности.
Создание правил
В моделях ANFIS используется нечеткое правило Такаги–Сугено–Канга (TSK). Правила TSK имеют следующую форму:
Если x1 относится к A1 и x2 относится к A2 и … и xn относится к An, то y = f (x1, x2, …, xn).
Количество правил TSK рассчитывается по следующему выражению:
Количество правил = (Количество функций принадлежности для признака 1) ^ (Количество признаков),
где Количество функций принадлежности для признака 1 – это количество функций принадлежности, используемых для представления первого признака;
Количество признаков – это количество входных признаков в модели ANFIS.
Во избежание усложнения работы модели и увеличения числа правил TSK целесообразно сократить количество входных признаков: для каждого изображения будет взято среднее значение признака Харалика по каналам, например, для контраста:
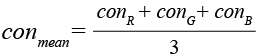 . (10)
. (10)
Таким образом, число входных признаков сократится до 4, а значит количество правил TSK в модели ANFIS для классификации изображений на 8 классов будет равно 3^4 = 81. Каждая комбинация функций принадлежности соответствует одному правилу TSK.
Модель ANFIS обучается с использованием гибридного алгоритма, который сочетает градиентный спуск и метод наименьших квадратов.
Алгоритм обучения состоит из двух основных этапов.
Прямой проход:
– Для каждого обучающего образца вычисляются степени принадлежности каждой функции принадлежности.
– Вычисляются веса правил TSK, используя степени принадлежности в качестве весов. Для вычисления весов правил используется метод наименьших квадратов. Это гарантирует, что взвешенная сумма выходных значений правил наиболее точно соответствует целевому выходному значению.
– Вычисляется взвешенная сумма выходных значений правил, чтобы получить прогнозируемое выходное значение модели.
– Вычисляется ошибка между прогнозируемым и фактическим выходным значением.
Обратный проход:
– Ошибка распространяется назад через сеть, чтобы обновить параметры функций принадлежности и веса правил.
– Параметры функций принадлежности и веса правил настраиваются с использованием градиентного спуска, чтобы минимизировать ошибку.
На этапе обратного прохода для настройки параметров функций принадлежности и весов правил используется градиентный спуск. Градиент ошибки рассчитывается относительно этих параметров, и они обновляются в направлении, который минимизирует ошибку.
Прямой и обратный проходы повторяются до тех пор, пока не будет достигнуто заданное количество эпох или пока ошибка не будет сведена к минимуму.
Таким образом, модель ANFIS для решения текущей задачи имеет следующие параметры:
– Количество входов: 4
– Количество выходов: 8 (1 общий)
– Количество функций принадлежности для каждого признака: 3
– Количество правил: 81
– Веса инициализируются случайными значениями и обучаются с помощью обратного распространения.
Код инициализации и обучения модели представлен на рис. 5.
РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
Непосредственно классификация, помимо модели ANFIS, выполнялась еще тремя инструментами:
– сверточной архитектурой нейронной сети (CNN, MobileNetV2);
– классическим алгоритмом машинного обучения – логистической регрессией;
– базовой моделью искусственной нейронной сети – персептроном (ANN).
Результаты приведены в сравнительной таблице.
Таблица
Результаты классификации
Метод классификации | Метрика | |||
accuracy | precision | recall | f-score | |
ANFIS | 85 % | 0,85 | 0,84 | 0,84 |
CNN (MobileNetV2) | 93 % | 0,92 | 0,93 | 0,92 |
Логистическая регрессия | 84 % | 0,84 | 0,83 | 0,84 |
ANN | 82 % | 0,82 | 0,83 | 0,82 |
Примечание: составлено авторами.
Как можно видеть из таблицы, CNN на базе MobileNetV2, использующей глубинно-разделимую свертку, справляется с задачей лучше прочих инструментов классификации, но ANFIS имеет перспективы улучшения – оптимизации параметров, в частности интеграции с генетическим алгоритмом или методами кластеризации.
Полученные результаты показывают, что ANFIS может эффективно классифицировать болезни растений с высокой точностью. Использование текстурных признаков Харалика в качестве входных параметров оказалось полезным для различения болезней растений. Гибридный алгоритм обучения обеспечил быструю сходимость и хорошую точность.
Несмотря на то что CNN на основе MobileNetV2 лучше справилась с задачей, ANFIS является перспективным инструментом для классификации болезней растений. Дальнейшие исследования могут быть направлены на расширение набора данных, исследование других признаков и оптимизацию архитектуры ANFIS для улучшения производительности, в частности целесообразно интегрировать в модель генетический алгоритм.
1. Гурлина Е. В. Разработка метода выявления текстурных свойств заданных классов изображений с использованием признаков Харалика // Перспективные информационные технологии (ПИТ 2020) : труды Междунар. науч.-технич. конф., 21–22 апреля 2020 г., г. Самара. Самара : Самарский научный центр РАН, 2020. С. 112–116.
2. Lofstedt T., Brynolfsson P., Asklund T. Gray-level invariant Haralick texture features // PLoS ONE. 2019. Vol. 14, no. 2. P. e0212110.
3. Брыкин В. В., Брагинский М. Я., Тараканов Д. В. и др. Классификация состояния растений средствами текстурного вейвлет-анализа и машинного обучения // Вестник кибернетики. 2024. Т. 23, № 1. С. 23–30. DOI 10.35266/1999-7604-2024-1-3.
4. Vyas A., Paik J. Review of the application of wavelet theory to image processing // IEIE Transactions on Smart Processing & Computing. 2016. Vol. 5, no. 6. P. 403‒417. DOI 10.5573/IEIESPC.2016.5.6.403.
5. Балаганский А. Ю., Гребеньков А. А. Вейвлет-преобразование для обработки изображений системы управления отоплением с применением методов машинного обучения // Информация и образование: границы коммуникаций. 2022. № 14. С. 147–150.
6. Mahajan V., Dhumale N. R. Leaf disease detection using fuzzy logic // International Journal of Innovative Research in Science, Engineering and Technology. 2018. Vol. 7, no 6. P. 6801–6807. DOI 10.15680/IJIRSET.2018.0706067.
7. Ashish P., Tanuja P. Survey on detection and classifi cation of plant leaf disease in agriculture environment // International Advanced Research Journal in Science, Engineering and Technology. 2017. Vol. 4, no. 4. P. 137–139. DOI 10.17148/iarjset/nciarcse.2017.40.
8. Thyagharajan K. K., Kiruba Raji I. A review of visual descriptors and classifi cation techniques used in leaf species identifi cation // Archives of Computational Methods in Engineering. 2019. Vol. 26. P. 933–960. DOI 10.1007/s11831-018-9266-3.
9. Алгоритм обучения anfis. URL: https://studfile.net/preview/9501084/page:11/ (дата обращения: 05.04.2024).
аспирант
кандидат технических наук, доцент
кандидат технических наук, доцент
аспирант, инженер 1 категории
Брыкин В.В., Брагинский М.Я., Тараканов Д.В., Назарова И.Л. КЛАССИФИКАЦИЯ СОСТОЯНИЯ РАСТЕНИЙ С ИСПОЛЬЗОВАНИЕМ АДАПТИВНОЙ НЕЙРО-НЕЧЕТКОЙ ИНФЕРЕНЦИОННОЙ СИСТЕМЫ (ANFIS). Вестник кибернетики. 2024;23(2):23-30. https://doi.org/10.35266/1999-7604-2024-2-3
Brykin V.V., Braginsky M.Ya., Tarakanov D.V., Nazarova I.L. CLASSIFYING PLANTS’ HEALTH USING AN ADAPTIVE NEURO-FUZZY INFERENCE SYSTEM (ANFIS). Proceedings in Cybernetics. 2024;23(2):23-30. (In Russ.) https://doi.org/10.35266/1999-7604-2024-2-3
628412, Ханты-Мансийский автономный округ – Югра,
г. Сургут, пр. Ленина, 1.
БУ ВО ХМАО-Югры «Сургутский государственный университет»
Email: science.jоurnals@surgu.ru











