


ТЕХНИЧЕСКИЕ НАУКИ

Для повышения дебита нефтяных и газовых скважин нефтегазодобывающие компании проводят работы по текущему и капитальному ремонту скважин с применением мобильных буровых комплексов, оснащенных системами верхнего привода (СВП). Собраны и проанализированы статистические данные по эксплуатации более 60 СВП на месторождениях Западной Сибири. Выполнен расчет основных показателей надежности СВП – вероятность безотказной работы и интенсивность отказов. Полученные результаты могут быть использованы для совершенствования системы технического обслуживания и ремонта бурового оборудования. Недостаточный уровень надежности элементов СВП в сочетании с экстремальными условиями эксплуатации на месторождениях Западной Сибири приводит к отказам и остановке всего технологического процесса ремонта скважин, что влечет за собой необходимость проведения ремонтно-восстановительных работ. Учитывая высокие требования к надежности бурового оборудования, эксплуатируемого на опасных производственных объектах, а также с целью непрерывности выполнения работ по текущему и капитальному ремонту скважин задачи повышения надежности СВП являются приоритетными для нефтегазодобывающих компаний.
Статья посвящена проблеме оценивания логистических регрессий, в которых объясняемая переменная принимает только два значения – 0 и 1. Прогнозные значения объясняемой переменной оцененной логистической регрессии трактуются как вероятности возникновения некоторого события, поэтому такие модели находят широкое применение при решении задач классификации. Для оценивания логистических регрессий на практике в основном используется метод максимального правдоподобия, реализованный во многих современных статистических пакетах. Один из его недостатков, например, в том, что в случае полной разделимости объектов на два класса он не дает единственных оценок. В работе предложен новый метод оценивания логистических регрессий. Условно его можно разбить на два этапа. Первый этап состоит в решении специальным образом сформулированной задачи линейного программирования, благодаря чему находятся весовые коэффициенты линейной комбинации объясняющих переменных. По сути, уже на этом этапе осуществляется классификация. Второй этап состоит в калибровке масштаба вероятностей. На основе реальной выборки объема 100 проведены вычислительные эксперименты. Новый метод доказал свою работоспособность при полной разделимости объектов на два класса. К тому же по количеству корректно предсказанных случаев новый метод ни разу не уступил методу максимального правдоподобия, а в одном из экспериментов и вовсе превзошел его.

В данной работе используется адаптивная нейро-нечеткая система ANFIS для классификации восьми болезней растений. В качестве входных данных системы применяются текстурные признаки Харалика, извлеченные из изображений растений. Обучение ANFIS проводилось с использованием гибридного алгоритма, сочетающего обратное распространение ошибки и градиентный спуск. Эффективность ANFIS оценивалась на тестовом наборе посредством вычисления точности, полноты и F1-меры. Полученные показатели подлежали сравнению с другими современными средствами классификации.
Рассмотрен ручной способ оценки слов и расчет их тональности в задаче формирования тонального словаря. В работе предложен метод моделирования оценки слов респондентами при прохождении анкетирования методом «best-worst scaling» для расчета эмоционального окраса слов. Содержание метода моделирования заключается в использовании готовых «словарей-ориентиров», служащих для вычисления статистических вероятностей предполагаемого выбора ответа в заданном вопросе анкеты. Введение коэффициента ошибки позволит учесть человеческий фактор в процессе выбора элементов. Реализация данного метода позволит выявить влияние распределения слов для оценивания, а также минимальное количество респондентов для формирования адекватных результатов, ожидаемых по сравнению со «словарем-ориентиром».
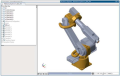
В работе описана последовательность действий, необходимых для решения прямой задачи кинематики, ориентированной на шестизвенного робота-манипулятора FANUC Robot M-20iA/35M. Решение задачи базируется на использовании современных технологий твердотельного CAD-моделирования совместно со средой физического моделирования, многозвенных пространственных механизмов SimMechanics системы Simulink. Среда SimMechanics системы Simulink используется для визуализации динамики движения рабочего органа манипулятора. Полученное выражение матрицы манипулятора позволит в дальнейшем использовать его для решения обратной задачи кинематики.
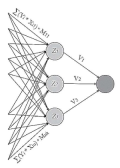
В данной работе предложен способ построения архитектуры нейронной сети для решения задачи классификации пользователей на основании сделанных ими комментариев, размещенных в открытых источниках. Для обучения нейронной сети применяется метод обратного распространения ошибки. Данные для обучения были предварительно размечены, а затем выборку разбили на три части, а именно тренировочную, валидационную и тестовую. Потребовалось провести предобработку отзывов покупателей до того, как они подавались на вход сети. Для реализации построенной модели было необходимо создать специальные словари слов, показывающих принадлежность к определенному классу. На основании полученного выходного значения построенной сети можно сделать вывод о том, к какой категории следует отнести определенных покупателей. Это позволит предприятию эффективно применять таргетированную рекламу к выявленной целевой группе потребителей.

В статье предложена методика, которая позволит выявить слепые зоны при тестировании программного обеспечения. Описаны общеизвестные проблемы в тестировании ПО и методики их решения. Описан способ, при помощи которого удастся выявить ту или иную проблему. Также продемонстрирован пример реализации этого способа.
Эффективным способом увеличения прибыли и укрепления рентабельности аптеки становится внедрение принципов автоматизации и управления деятельностью фармацевта с помощью информационных систем. Компании используют алгоритмы машинного обучения для корректировки своей стратегии, изучения отношения клиентов к своей организации посредством анализа отзывов и для повышения имиджа фирмы. Однако ручная обработка поступающих отзывов требует значительного времени и усилий фармацевта. Автоматизировать данный вид деятельности в статье предлагается за счет алгоритма наивного байесовского классификатора, реализованного средствами Python. Для обучения классификатора был создан собственный корпус размеченных текстов отзывов с двумя категориями, суммарное количество отзывов около 500. Для поиска отзывов использовался парсер, написанный на Python. В рамках предварительной обработки текста отзывов были выполнены: лемматизация, удаление знаков пунктуации, процедура приведения текста к нижнему регистру, токенизация и удаление стоп-слов, а в качестве способа векторизации текста был выбран метод «Bag of Words», или мешок слов. Согласно проведенным численным экспериментам, наивысшая точность классификатора достигалась при соотношении обучающей и тестовой выборки 80/20, без стоп-слов. При использовании классификатора на анализ 100 отзывов потребуется в восемь раз меньше времени по сравнению с их чтением человеком. Сам классификатор может быть представлен как отдельное приложение или как модуль информационной системы. Таким образом, растущее количество положительных отзывов у фирмы является показателем ее успешной работы и числа довольных клиентов, а рост имиджа позволит увеличить доверие покупателей к фирме и приведет к росту продаж.
В последние годы в сфере IT наблюдается увеличение интереса к инструментам автоматизации бизнес-процессов без кода. Инвестиции в no-code платформы за последние пять лет превысили миллиард долларов. Особое внимание уделено анализу вышеуказанных технологий в разрезе малого и крупного бизнеса. Однако вопрос о замене классической разработки остается. Исследование ставит цель выяснить, кому полезно использовать no-code, а кому классическую разработку. Актуальность темы обусловлена ограниченностью ресурсов компаний. Методы включают анализ эффективности и сравнение результатов внедрения. Преимущества no-code включают скорость, стоимость и низкие риски, но есть зависимость от программного решения и необходимость в навыках программирования. Исследование призывает к балансу между использованием no-code и классической разработкой для максимизации выгоды. На основе исследования установлено, что no-code и low-code разработка малоэффективна без классического программирования и будет более результативна для внедрения в компании, которые уже содержат штат IT-специалистов.
В работе рассмотрен такой важный аспект компьютерного зрения, как формирование признаков распознавания объектов, в системах технического зрения. Подобные системы, нашедшие широкое применение в различных отраслях промышленности, дают возможность получить большой объем быстро собираемой информации. При этом cобирается информация о свойствах наблюдаемых объектов, в число которых зачастую относят перемещение, а также геометрические параметры их формы. Авторами предлагается использование признаков распознавания объектов, в основе которых лежат ортоэкспоненциальные функции и которые сохраняют в себе информацию о форме исследуемого объекта. Для контуров некоторых правильных геометрических фигур приведены примеры вычисленных комплексных значений элементов матрицы формы, получаемой на основе коэффициентов разложения рассматриваемых в работе ортоэкспоненциальных функций.
ФИЗИКО-МАТЕМАТИЧЕСКИЕ НАУКИ
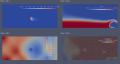
Проведено экспериментальное исследование и численное моделирование распространения фронта пламени по стратифицированной газовой смеси в плоском канале малого поперечного размера, образованного двумя параллельными пластинами. Получены изображения фронта пламени методом прямого фотографирования. Обнаружено изменение формы пламени при колебательном распространении в длинном канале. Построены поля распределения температур, концентрации газа, давления, скорости и линии тока. Показано, что результаты моделирования качественно совпадают с результатами экспериментов.











