


Содержание
Перейти к:
https://doi.org/10.35266/1999-7604-2024-2-4
Перейти к:
Рассмотрен ручной способ оценки слов и расчет их тональности в задаче формирования тонального словаря. В работе предложен метод моделирования оценки слов респондентами при прохождении анкетирования методом «best-worst scaling» для расчета эмоционального окраса слов. Содержание метода моделирования заключается в использовании готовых «словарей-ориентиров», служащих для вычисления статистических вероятностей предполагаемого выбора ответа в заданном вопросе анкеты. Введение коэффициента ошибки позволит учесть человеческий фактор в процессе выбора элементов. Реализация данного метода позволит выявить влияние распределения слов для оценивания, а также минимальное количество респондентов для формирования адекватных результатов, ожидаемых по сравнению со «словарем-ориентиром».
Гончаров А.Р., Лысенкова С.А. МЕТОД МОДЕЛИРОВАНИЯ ОЦЕНКИ СЛОВ РЕСПОНДЕНТОМ ДЛЯ ПРОГНОЗА СИЛЫ ТОНАЛЬНОСТИ ЭЛЕМЕНТОВ В ТОНАЛЬНОМ СЛОВАРЕ. Вестник кибернетики. 2024;23(2):31-38. https://doi.org/10.35266/1999-7604-2024-2-4
Goncharov A.R., Lysenkova S.A. MODELING METHOD FOR RESPODENT’S ANALYSIS OF WORDS FOR PREDICTING SENTIMENT ANALYSIS OF SENTIMENT DICTIONARY’S ELEMENTS. Proceedings in Cybernetics. 2024;23(2):31-38. (In Russ.) https://doi.org/10.35266/1999-7604-2024-2-4
Анализ мнений и оценок людей в интернет-среде по отношению к различным объектам (качество услуг, товаров, реакции на события и т. п.) становится популярным направлением исследования, получившим большое распространение из-за роста объема доступной текстовой информации. Сентимент-анализ (или анализ тональности), областью которого является компьютерная лингвистика, занимается вопросами по автоматическому извлечению эмоционально-смысловой информации из сообщений пользователей с целью формирования тональной оценки [1]. Под «тональностью» в общем случае понимается субъективная модальность текста – выражение эмоционально-волевой установки автора по отношению к объекту или теме повествования в сформулированных им текстовых данных посредством применения лексических единиц (слов, словосочетаний и т. п.). Важно отметить, что лексические единицы, на основе которых определяют тональность, не являются прямыми выразителями эмоций, а только передают понятие о них в узком эмоциональном спектре [2]. Поэтому в работах по тональному анализу текста данное отношение выражается категорией, имеющей полярность «негативность–положительность», где текст соотносят к одной из групп эмоций: положительной, отрицательной или нейтральной.
В настоящее время сентимент-анализ реализуется на основе методов машинного обучения, правил или применения словарей с оценочной лексикой (тональных словарей). Такие структуры содержат специально выделенные слова и словосочетания, применяемые в рамках одной предметной области или теме повествования и несущие эмоциональный окрас, который выражается номинально (например, в словарях «РуСентиЛекс-2017», «Словарь Блинова»), количественно («LINIS Crowd») или в смешанном варианте («КартаСловСент»).
В работе [3] представлен систематический обзор существующих тональных словарей, а также основные способы их формирования, среди которых выделяют автоматический и ручной. Ручной способ предполагает привлечение экспертов или носителей языка (краудсорсинг), усилиями которых происходит эмоциональная классификация (разметка) слов будущего словаря. В основе данного способа лежит процесс «классического» анкетирования, где каждому участнику (респонденту) предлагают назначить оценки предложенным элементам в соответствии с заданной шкалой тональности и рассматриваемым контекстом. Так, например, при составлении русскоязычного словаря «LINIS Crowd» респонденты оценивали элемент словаря по пятибалльной шкале [4], а в формировании словаря «КартаСловСент» определяли тональность элемента, выбрав один из четырех предложенных вариантов ответа (рис. 1) [5]. В результате разметки слов «классическим» анкетированием каждому элементу присваивается эмоциональная группа на основе статистики выбора элементов.
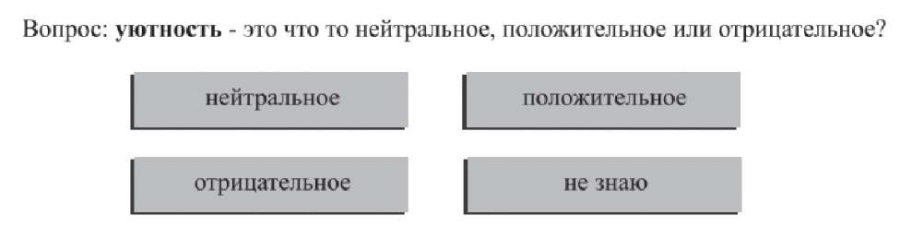
Рис. 1. Пример вопроса, задаваемого в рамках «классической» разметки слов
Примечание: рисунок по [5] с изменениями.
Существует другой вариант проведения анкетирования для разметки слов словаря – метод «наилучшее–наихудшее масштабирование» (best-worst scaling, BWS) [6], который применялся при составлении англоязычного словаря «NRC-EIL» [7]. Суть данного метода заключается в том, что респонденту предлагают выбрать два различных элемента из предложенного ему списка слов (кортежа) из одной эмоциональной группы по наилучшему и наихудшему рассматриваемому свойству. Так, например, из списка слов необходимо выбрать два разных элемента, которые передают в большей и меньшей степени соответственно проявление эмоции «гнев» (рис. 2). В результате разметки слов BWS-методом образуются сравнительные пары отношения элементов, из которых рассчитывают степень проявления эмоции ωw по формуле:
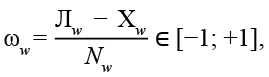
где ωw = –1 – наименьшая степень проявления тональности слова w;
ωw = +1 – наивысшая степень проявления тональности слова w;
Nw – количество вхождений слова w в разные списки;
Лw– количество оценок слова w как обладающим «наилучшим» свойством;
Xw– количество оценок слова w как обладающим «наихудшим» свойством.
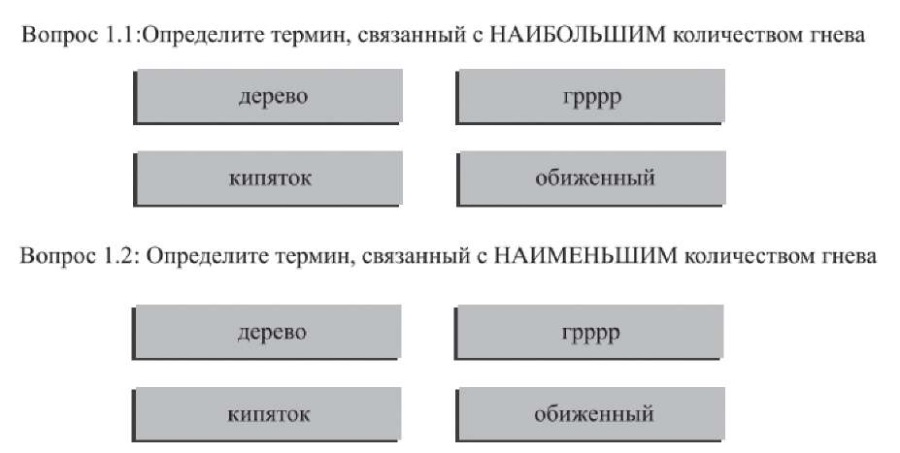
Рис. 2. Пример вопроса, задаваемого в рамках разметки слов по BWS-методу
Примечание: рисунок по [7] с изменениями.
Несмотря на то что большинство русскоязычных словарей построены вручную [3], такой способ формирования словарей остается популярным, так как обеспечивает высокую точность классификации слов с учетом лингвистических особенностей естественного языка [8]. Однако ручной способ не обделен недостатками: субъективность характера ответов респондентов, субъективность исследователя при составлении вопросов в анкете, неопределенность трактовки вопросов, затраты времени на обработку и др. Уменьшение влияния первых двух недостатков достигается путем совершенствования методов составления анкет [9]. Результаты анкетирования позволят выявить закономерности распределения слов в вопросах для дальнейшего формирования «оптимальных» анкет, помогающих снизить неопределенность в процессе выбора респондентом, который может испытывать трудности в силу «близости» рассматриваемых свойств элементов.
Поэтому целью данной работы является предложить метод моделирования оценки слов респондентами в анкетировании, позволяющий предсказать полученные результаты в формировании тонального словаря ручным способом. Такое моделирование подразумевает решение следующих задач:
– определить содержательную часть вопросов анкет, где количественно оценить значение распределения слов и их влияние на итоговый результат;
– определить минимальное количество требуемых респондентов для получения адекватных результатов анкетирования и расчета эмоционального окраса слов;
– определить предельное количество предлагаемых респонденту вопросов, после которых предполагается совершение им ошибок.
В результате работы описан метод моделирования выбора респондентами в анкетировании методом BWS на основе расчета статистических вероятностей из выбранного «словаря-ориентира».
Предлагаемый метод моделирования оценки слов анкетированием по BWS-методу основывается на применении статистических вероятностей выбора того или иного элемента. Такие вероятности рассчитываются из существующих тональных словарей.
Пусть исследователь формирует анкету A для респондентов по BWS-методу для расчета силы эмоционального окраса слов в тональном словаре, содержащая N вопросов: Q1, Q2, ..., QN . Каждый вопрос состоит из списка различных оценочных слов размерностью 4 элемента: Qi = (qi1, qi2, qi3, qi4). Также каждый элемент для разметки должен встречаться в восьми разных вопросах. Такое распределение позволяет сформировать ранжированные оценки и значительно сократить количество операций оценки в сравнении с классическим попарным сравнением элементов. Так, при составе словаря из N элементов BWS-методом требуется 4N вопросов при их разделении в выборе как наихудшего и наилучшего элемента, в то время как классическое попарное сравнение требует N² вопросов.
Отмечено, что список слов и словосочетаний, включенных в итоговый словарь, составляется на основе существующих словарей оценочной лексики либо извлекается из общих текстовых массивов, что говорит о схожести содержательного состава различных словарей (их пересечение) [3]. Пересечение словарей проявляется в близости эмоционального окраса некоторых слов, что связано в первую очередь с особенностями рассматриваемого языка и контекста их применения. Это означает, что при формировании тонального словаря эмоциональный окрас некоторых слов будет схожим с другими из существующих словарей. Данная особенность позволяет использовать некоторый готовый тональный словарь как «ориентир» при составлении иного. Важно отметить, что в данном контексте работы в качестве такого словаря подходят только те, которые содержат количественные значения силы проявления тональности. Так, для моделирования оценки англоязычных слов можно использовать словарь «NRC-EIL-2022», а для русскоязычных – «КартаСловСент».
В данной работе в качестве примера «словаря-ориентира» использован словарь «КартаСловСент» с предварительным нормированием коэффициентов значений силы тональности в диапазоне от 0 до 1. Можно вывести предположение, что элементы с высоким значением коэффициента выбираются чаще респондентами как «наилучший» по рассматриваемому свойству тональности, а низкое значение коэффициента – как «наихудший». В табл. 1 приведен пример содержания данного словаря группы «positive» с предварительным нормированием коэффициентов по методу «минимакс».
Таблица 1
Пример элементов группы «positive» словаря «КартаСловСент»
Элемент | Интенсивность тональности |
ангельский | 1,000 |
безвинный | 0,870 |
аромат | 0,835 |
безмятежный | 0,775 |
Примечание: составлено по [5].
Согласно данной таблице при предоставлении респонденту кортежа слов Q = (ангельский, безвинный, аромат, безмятежный) с большей вероятностью можно утверждать, что элемент «ангельский» респондент выберет как «наилучший», а «безмятежный» – как «наихудший» по свойству «позитивности». Однако при формировании статистической вероятности выбора элементов возникает ряд вопросов:
– Насколько элемент A выбирают чаще, чем B?
– Насколько вероятность выбора A различается с выбором элемента B?
Такая установка задает «силу» различия вероятностей элементов, что корректно, так как сам метод BWS анкетирования и расчета эмоционального окраса слов подразумевает исключительно формирование сравнительных пар. Исследователь предположительно на основе количественных показателей в «словаре-ориентире» может реконструировать изначально предполагаемое сравнительное отношения выбора элементов.
Так, расчет статистических вероятностей предполагаемого выбора ответа как «наилучшего» респондентом в заданном вопросе Q сводится к определенному алгоритму:
В Q = (ангельский, безвинный, аромат, безмятежный) на основе «словаря-ориентира» (табл. 1) сформировать сравнительное отношение: безмятежный < аромат < безвинный < ангельский.
Для самого наихудшего элемента в данном отношении принять вероятность выбора респондентом за p. Для остальных вероятностей выбора элементов присвоить количественное отношение по сравнению с «наихудшим» элементом согласно коэффициенту из «словаря-ориентира» (табл. 1), беря за расчет только значение из дробной части. Значение из дробной части берутся до n-го знака после запятой. В данном случае n = 3. Кроме того, при коэффициенте силы тональности из словаря ориентира, равном 1,0, необходимо взять значение 10n:
P(безмятежный) = p,
P(аромат) = (835–775)p = 60p,
P(безвинный) = (870–775)p = 95p,
P(ангельский) = (1000–775)p = 225p.
Далее необходимо просуммировать данные вероятности и решить простое математическое уравнение вида p + 60p + 95p + 225p = 1.
Найдя p, рассчитать другие вероятности выбора элементов в вопросе согласно составленному выражению на предыдущем шаге:
P(безмятежный) ≈ 0,0026,
P(аромат) ≈ 0,156,
P(безвинный) ≈ 0,247,
P(ангельский) ≈ 0,585.
При использовании случайной величины R ∈ [0,1] можно воссоздать предполагаемую ситуацию выбора респондентом «наилучшего» элемента в вопросе Q по свойству «позитивности». Так образуются пары элементов с их предполагаемой вероятностью выбора < (безмятежный, 0,0026), (аромат, 0,156), (безвинный, 0,247), (ангельский, 0,585) > (рис. 3).

Рис. 3. Распределение выбора «наилучшего» элемента
респондентом в Q относительно случайной величины R
Примечание: составлено авторами.
При моделировании выбора «наихудшего» элемента необходимо вновь рассчитать статистические вероятности по заданному алгоритму, беря во внимание тот факт, что требуется скорректировать заданные значения интенсивности тональности «словаря-ориентира» y по формуле y* = 1,0 – y (табл. 2).
Таблица 2
Корректировка элементов словаря «КартаСловСент»
Элемент | Интенсивность тональности |
ангельский | 0,000 |
безвинный | 0,130 |
аромат | 0,165 |
безмятежный | 0,225 |
Примечание: составлено авторами.
Предложенный алгоритм расчета статистических вероятностей выборов элементов с использованием случайной величины позволяет спрогнозировать предполагаемый выбор элементов респондентом в анкетировании методом BWS. В рассмотренном выше примере можно сделать вывод, что прослеживается влияние распределения элементов в вопросах. Так, при предоставлении «близких» элементов респонденту, значения силы тональности которых по словарю-ориентиру приблизительно равны, выбор респондента можно свести к равномерному или хаотичному явлению. Конечно, при составлении иного тонального словаря и расчета тональности в другой предметной области, когда похожих словарей еще попросту не существует, трудно определить предполагаемую близость оценочных элементов. Однако, учитывая факт пересечения словарей из разных предметных областей, можно выявить обобщенные элементы и предположить о возможной их тональности.
Предложенный метод моделирования не учитывает «индивидуальность» респондента, которая может проявляться по-разному (пол, возраст, регион проживания и т. д.). В данном случае необходимо ввести фактор совершения ошибки респондентом, который можно интерпретировать как его невнимательность или утомляемость при прохождении анкетирования. Для добавления случайности фактора ошибки респондентом требуется ввести коэффициент ошибки err, который будет сводить каждую вероятность выбора элемента P(w) к ¼, что равносильно равномерному распределению. Так, с каждым новым вопросом Q требуется корректировать каждую вероятность выбора элемента формулой:
P(w)′ = P(w) – err • k, (2)
где err = | P(w) – ¼|;
k – коэффициент роста ошибки, 0 ≤ k ≤ 1.
В свою очередь, коэффициент k подчиняется распределению 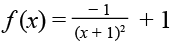 (рис. 4), где
(рис. 4), где 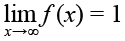 при x ≥ 0, а x – количество пройденных вопросов респондентом.
при x ≥ 0, а x – количество пройденных вопросов респондентом.
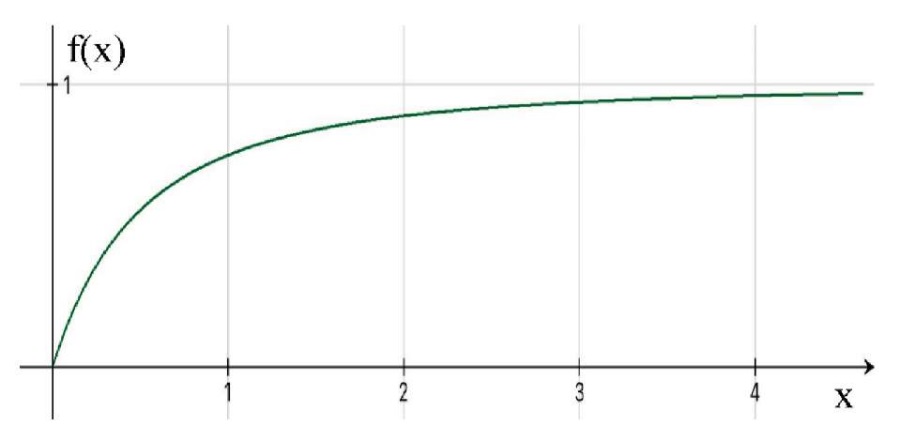
Рис. 4. График роста коэффициента k = f(x)
относительно пройденных респондентом вопросов анкеты
Примечание: составлено авторами.
Необходимо учесть масштабирование распределения k = f(x) под реальные задачи, так как уже при начальных значениях x наблюдается высокий рост коэффициента k. Поэтому введение дополнительного регулируемого параметра s, где 0 < s ≤ 1, позволит предотвратить высокий рост ошибки на начальных этапах анкетирования и тем самым задаст «индивидуальность» респондента, выраженного в степени его «утомляемости». Так, формула расчета коэффициента k с введением дополнительного параметра преобразуется в следующий вид:
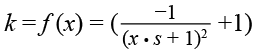 . (3)
. (3)
Такая корректировка позволит учесть человеческий фактор, когда респондент «утомляется» поочередно оценивать предложенные ему оценочные элементы.
Для выявления оптимального количества предлагаемых респонденту элементов и остановки процесса моделирования оценки элементов необходимо ввести метрику расчета вероятностей |P(w) − err| ≥ ε, где ε – допустимый предел, определяемый исследователем самостоятельно, при котором выбор «наилучшего» и «наихудшего» элемента не сводится к случайному выбору.
Предложенный метод расчета вероятностей выбора элементов и проведение моделирования их оценки респондентом методом BWS при помощи случайной величины позволит исследователю выявить оптимальное распределение слов для оценивания, а также минимальное количество респондентов для получения предполагаемых результатов в задаче формирования тонального словаря относительно «словаря-ориентира».
Использование тональных значений готовых словарей предполагает некоторую их общность содержания и контекст использования элементов. Тем не менее данная близость в применении разных предметных областей текста может существенно отличаться, что сказывается на автоматических алгоритмах определения тональности текста.
Важно учесть, что разброс значений в используемом «словаре-ориентире» оказывает немаловажную роль в процессе моделирования выбора элемента, так как предоставление близких по свойству элементов для оценки респонденту создаст трудности их выбора и интерпретации, что требует дальнейшего исследования.
1. Майорова Е. В. О сентимент-анализе и перспективах его применения // Социальные и гуманитарные науки. Отечественная и зарубежная литература. Серия 6: Языкознание. 2020. № 4. С. 78–86.
2. Матвеева Т. В. Тональность текста // Эффективное речевое общение (базовые компетенции) : словарь-справочник / под ред. А. П. Сковородникова. 2-е изд., перераб. и доп. Красноярск : Сиб. фед. ун-т, 2014. С. 692–694.
3. Котельников Е. В., Разова Е. В., Котельникова А. В. и др. Современные словари оценочной лексики для анализа мнений на русском и английском языках (аналитический обзор) // Научно-техническая информация. Серия 2: Информационные процессы и системы. 2020. № 12. С. 16–33. DOI 10.36535/0548-0027-2020-12-3.
4. Koltsova O. Yu., Alexeeva S. V., Kolcov S. N. An opinion word lexicon and a training dataset for Russian sentiment analysis of social media // Computational Linguistics and Intellectual Technologies : Proceedings of the International Conference “Dialogue 2016”, June 1–4, 2016, Moscow. Moscow, 2016. Vol. 15. P. 277–287.
5. Кулагин Д. И. Открытый тональный словарь русского языка КартаСловСент // Компьютерная лингвистика и интеллектуальные технологии : по материалам ежегодной междунар. конф. «Диалог», 16–19 июня 2021 г., г. Москва. Вып. 20. М. : Российский государственный гуманитарный университет, 2021. С. 1106–1119. DOI 10.28995/2075-7182-2021-20-1106-1119.
6. Flynn T. N., Marley A. A. J. Best-worst scaling: Theory and methods // Handbook of choice modelling / Hess S., Daly A., eds. Cheltenham, UK : Edward Elgar Publishing, 2014. P. 178‒201.
7. Mohammad S. M. Word affect intensities // Proceedings of the 11th International Conference on the Language Resources and Evaluation (LREC‒2018), May 7‒12, 2018, Miyazaki, Japan. URL: https://www.saifmohammad.com/WebDocs/word-affect-intensities.pdf (дата обращения: 25.03.2024).
8. Лукашевич Н. В. Автоматический анализ тональности текстов: проблемы и методы // Интеллектуальные системы. Теория и приложения. 2022. Т. 26, № 1. С. 50–61.
9. Вакуленко А. А., Стрелец А. В., Сытник Д. А. Методика оценки влияния качества анкеты на достоверность результатов анкетирования методом имитационного моделирования // Вестник Московского государственного областного университета. 2013. № 4. URL: https://elibrary.ru/download/elibrary_21206563_45223214.pdf (дата обращения: 25.03.2024).
аспирант
кандидат физико-математических наук, доцент
Гончаров А.Р., Лысенкова С.А. МЕТОД МОДЕЛИРОВАНИЯ ОЦЕНКИ СЛОВ РЕСПОНДЕНТОМ ДЛЯ ПРОГНОЗА СИЛЫ ТОНАЛЬНОСТИ ЭЛЕМЕНТОВ В ТОНАЛЬНОМ СЛОВАРЕ. Вестник кибернетики. 2024;23(2):31-38. https://doi.org/10.35266/1999-7604-2024-2-4
Goncharov A.R., Lysenkova S.A. MODELING METHOD FOR RESPODENT’S ANALYSIS OF WORDS FOR PREDICTING SENTIMENT ANALYSIS OF SENTIMENT DICTIONARY’S ELEMENTS. Proceedings in Cybernetics. 2024;23(2):31-38. (In Russ.) https://doi.org/10.35266/1999-7604-2024-2-4
628412, Ханты-Мансийский автономный округ – Югра,
г. Сургут, пр. Ленина, 1.
БУ ВО ХМАО-Югры «Сургутский государственный университет»
Email: science.jоurnals@surgu.ru











